
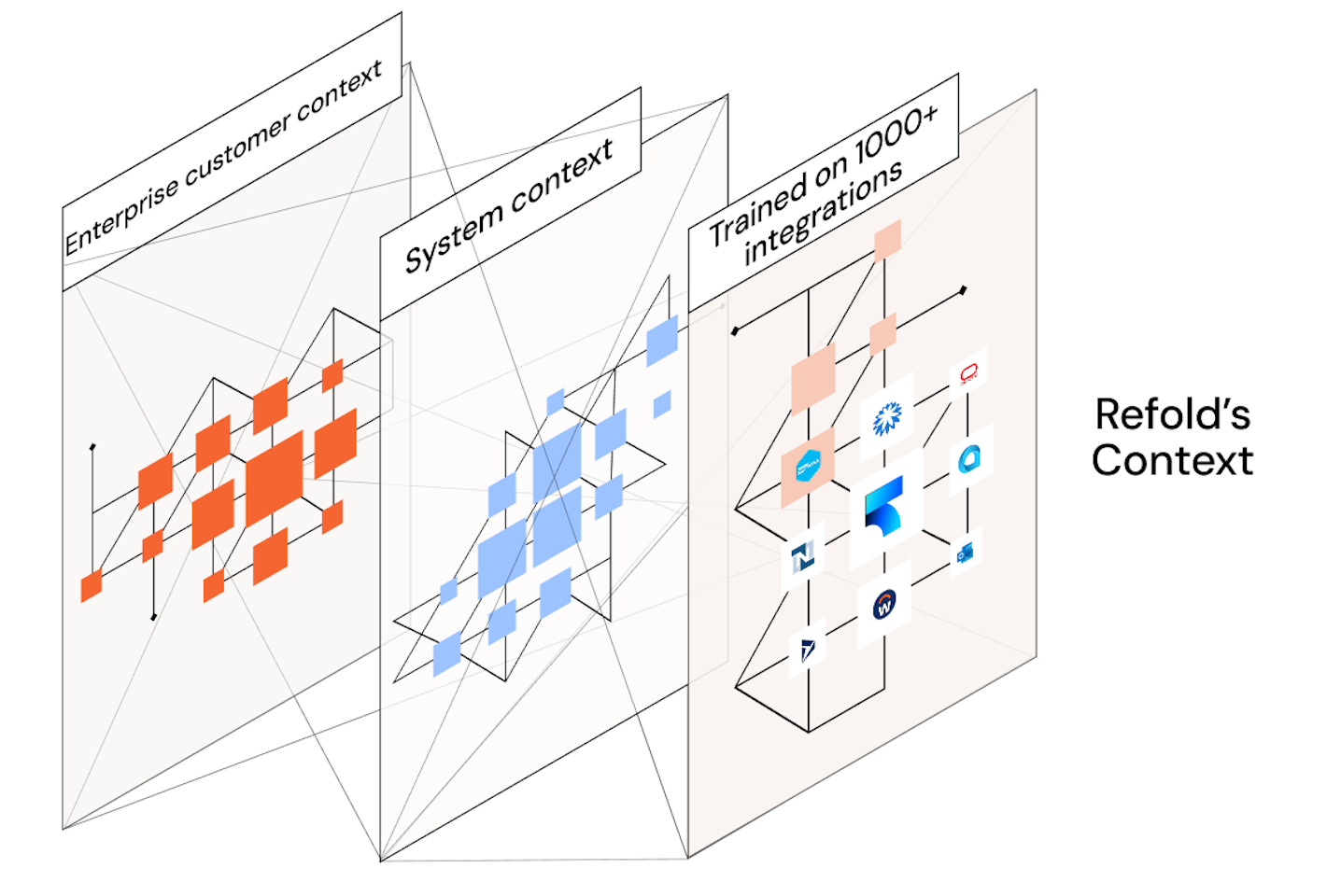
Where every integration decision, workaround, and mapping becomes reusable infrastructure
Today we're sharing the architecture behind how Refold learns from every integration it delivers: the Integration Graph.
Simply put, the Integration Graph is the system of record for everything an integration team learns. It remembers every mapping, every fix, every API quirk an engineer would have kept in their head. Each one is captured as a structured, queryable record, scored for confidence, and linked to the specific applications and fields it touches. That knowledge is then available to every future deployment.
It works differently from prior AI approaches:
- Unlike RAG, which retrieves chunks of text by keyword similarity, the Integration Graph retrieves by structural match. Every confidence-weighted pattern attached to this specific field on this specific object, across every prior deployment.
- Unlike fine-tuned models, which freeze knowledge at training time, the Integration Graph learns continuously.
- Unlike agent frameworks, which orchestrate within a session and forget between them, the Integration Graph compounds. Every integration starts with more context than the last.
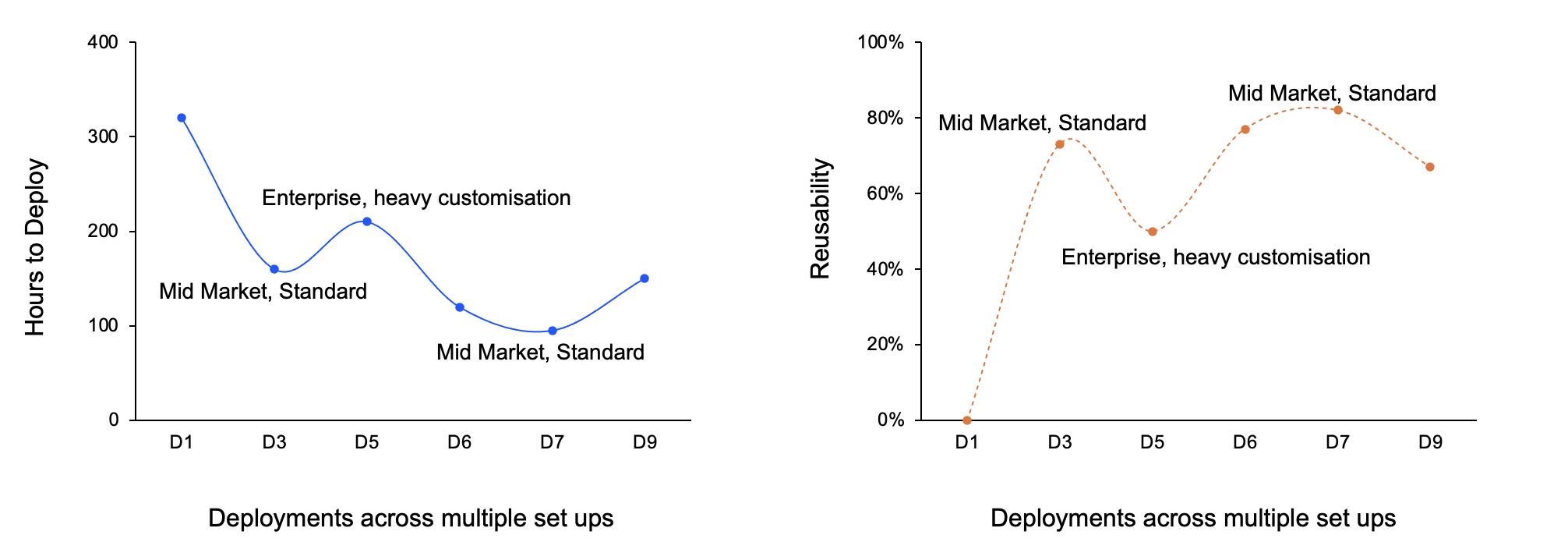
The impact, measured across 9 production deployments of the same SAP S/4HANA ↔ Salesforce connector pair, with the same 3-engineer team:
- 70% reduction in human-hours from cold-start to deployment 7, 320 hours down to 95
- 82% of fields auto-mapped by deployment 7, pulled directly from the graph
- Sublinear marginal cost, every deployment costs less than the last, because the reusable portion compounds while the tenant-specific portion shrinks
The challenge with enterprise integration today
We keep hearing the same two things from every integration team we talk to
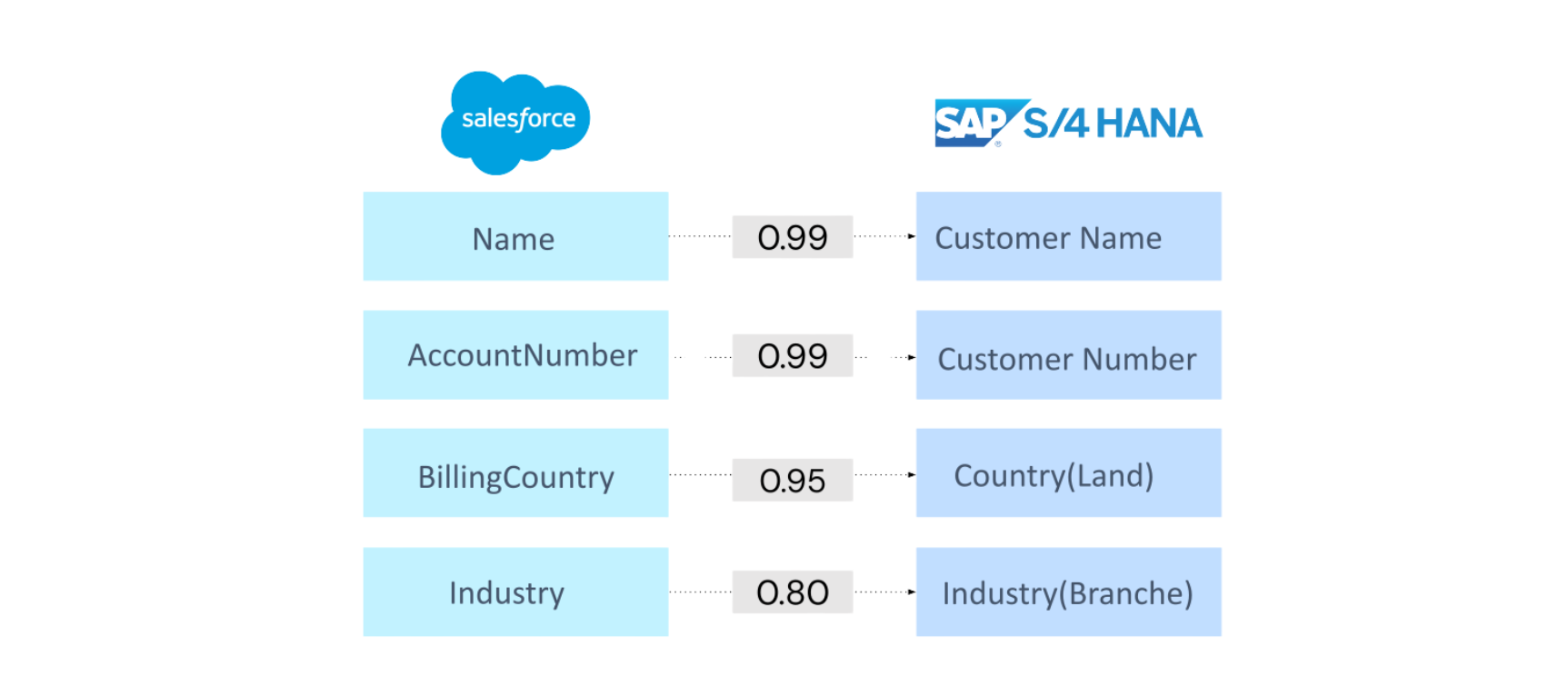
The first is that knowledge walks out the door. Every production SAP or Salesforce instance carries hundreds of custom fields with no record of why they exist. Systems integrator turnover runs 15–25% annually, so by the time Priority_Flag__c needs mapping, the engineer who could explain it is gone. Same for runtime knowledge — which API quirks differ from the docs, which errors cascade, which resolve on retry. Every team transition is a partial reset.
The second is that vendors ship change before changelogs. Customer A hits the break. An engineer ships a fix. A week later Customer B hits the same break, and the cycle runs again. Teams react to change; they don't anticipate it.
Across 200+ deployments of the same connector pairs — SAP↔Salesforce, SAP↔Coupa, NetSuite↔Shopify — we've watched the same pattern: most teams rebuild the solved part from scratch, then figure out the unsolved part from first principles. The industry has no system of record for the operational knowledge that keeps integrations working.
The issue isn't that AI can't reason about integrations. It's that the reasoning isn't persisted. RAG retrieves by keyword similarity, not operational relevance. Fine-tuned models freeze knowledge at training time. Agent frameworks orchestrate within a session and forget between them. Every approach we looked at treated intelligence as ephemeral.
How the Integration Graph works
The Integration Graph is powered by two primitives: Episodes and Patterns.
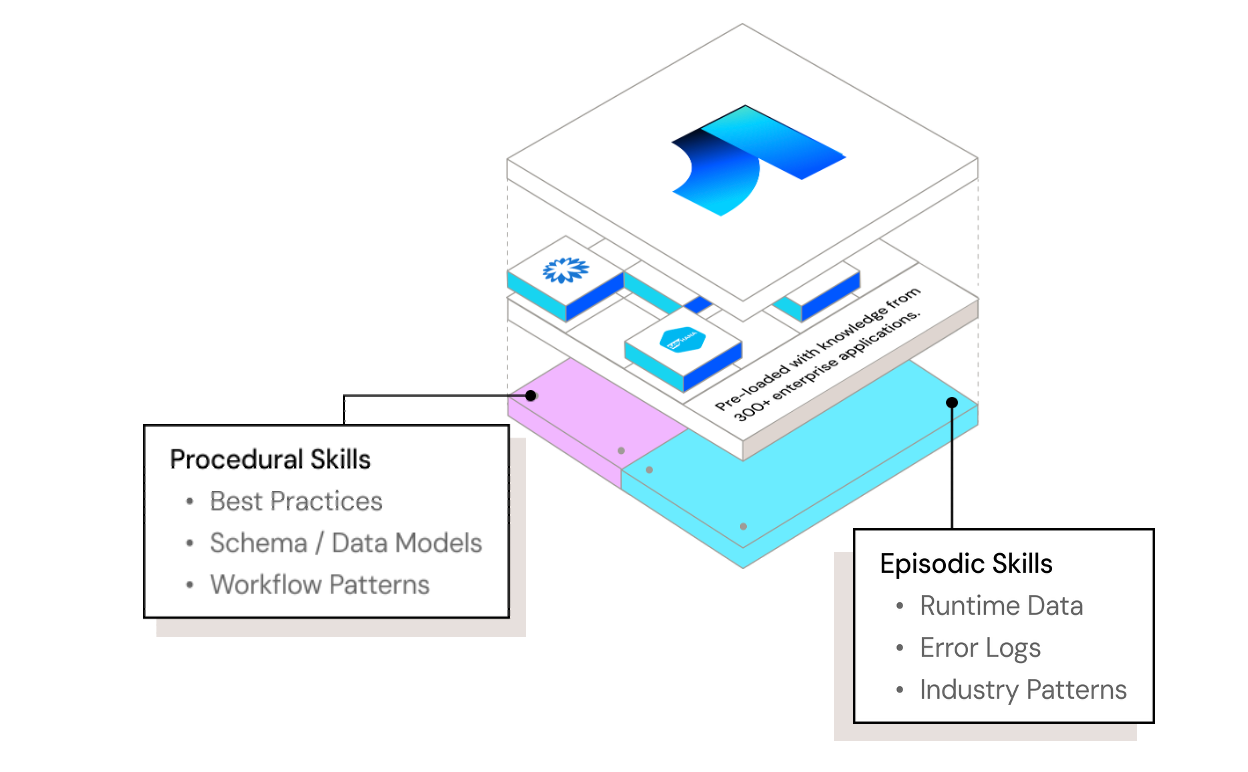
Episodes capture what happens during every deployment: every error hit, every fix applied, every human correction. This is how knowledge stops walking out the door when an engineer leaves. Patterns capture how systems actually connect: the recurring rules about field mappings, validation sequences, and API behaviors that today live in someone's head and get rebuilt from scratch on every new deployment.
When an agent runs a deployment, the full trace is captured automatically as an Episode and linked to the specific entities it touched. Over time, when the same behavior shows up across multiple Episodes ("validate currency fields against the local config before mapping"), the extraction pipeline lifts it into a Pattern: a typed rule with a trigger, an action, a confidence score, and a link to the entities it applies to.
The cycle is simple. Deploy, extract what was learned, enrich the graph, retrieve on the next deployment. Every deployment writes new Episodes. The pipeline lifts recurring behaviour into Patterns. The next deployment starts with more context than the last.
It works differently from a traditional knowledge base because every piece of knowledge carries a confidence score that decays over time if it isn't reinforced. The graph doesn't just accumulate. It stays current. Old knowledge that's no longer validated by real deployments fades out naturally, rather than persisting and misleading future agents.
What the Integration Graph unlocks in practice
As we deployed across more customers, we started seeing behaviours we hadn't explicitly designed for. They emerge from the architecture operating as a whole.
One customer's break becomes every customer's defence. When a vendor silently changes an API, the first customer to hit it captures the anomaly automatically, and every other customer on that connector inherits the defence before they ever see the break. We had an SAP field deprecation hit one customer on a Friday. By the following week, every other SAP deployment was already routing around it. No ticket filed, no engineer paged.
Fewer wrong mappings make it to production. The agent prioritizes decisions backed by dozens of prior deployments over superficially similar matches it's only seen once or twice. Not everything in the graph is equally trustworthy, and the system knows that. Every piece of knowledge carries a confidence score that decays if it isn't reinforced. Less rework, fewer post-go-live fires.
Past work stays findable, no matter how it was documented. Enterprise documentation is inconsistent at best. A fix logged as "locale configuration issue" six months ago will still surface when an agent is mapping a currency field today, because the underlying entities match, even if the terminology doesn't. The graph doesn't search by keywords; it traverses entity relationships.
New systems extend the graph, not break it. A large enterprise migrating from SAP ECC to S/4HANA introduced an entity type we hadn't anticipated. The system accepted it, we reviewed it, and now it's available to every future SAP migration.
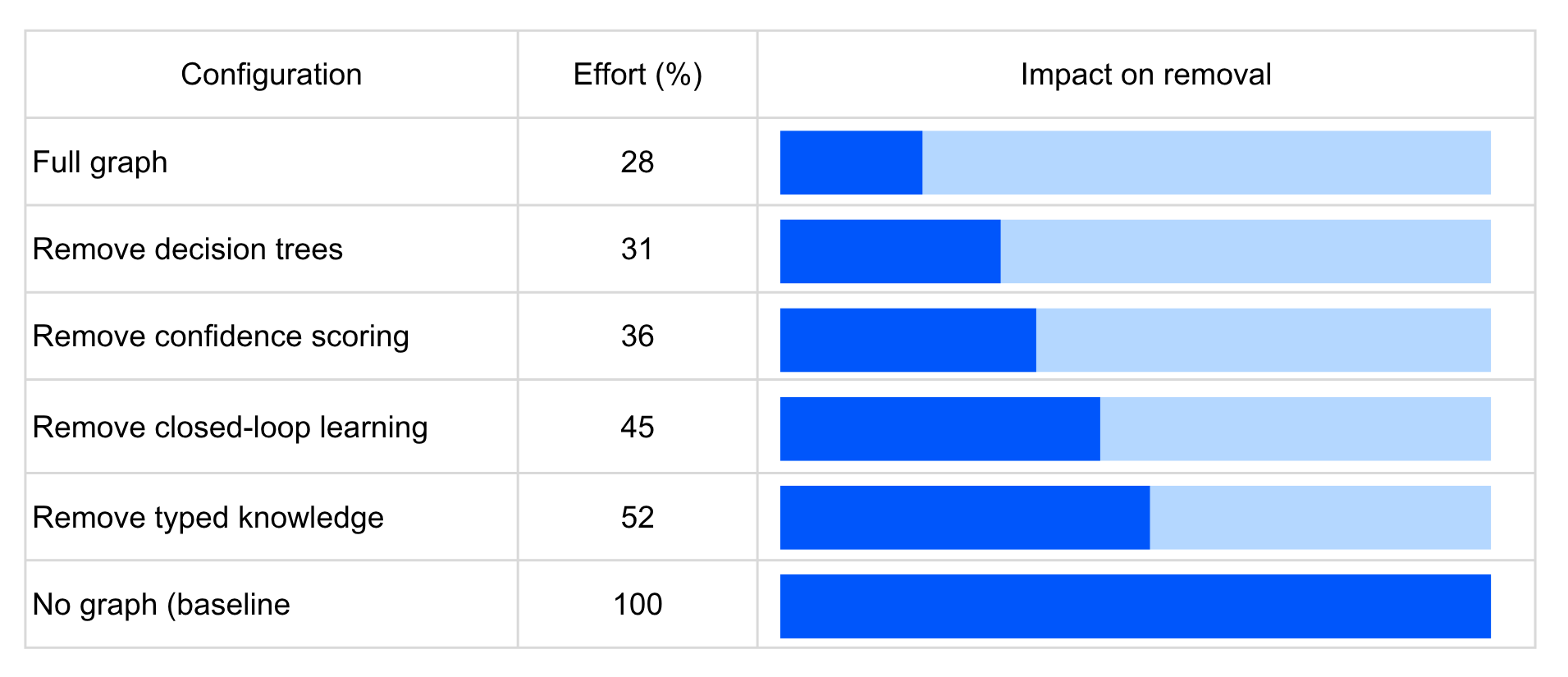
We validated these behaviours across 30 deployments by disabling each architectural property in turn. Typed knowledge had the highest impact: removing it nearly doubled effort. Closed-loop learning was second; without it, the graph helps but doesn't compound. Standard configurations hit 82% reuse. Heavily customized enterprises hit 50%. The reusable portion compounds; the tenant-specific portion shrinks. The learning pipeline runs on about 1–2 hours of human review per week.
Available today
The Integration Graph is live in production across our customer base. Every new SAP, NetSuite, Oracle, and Salesforce connector pair deployed through Refold is writing Episodes and extracting Patterns as we ship.
For ISVs and SaaS companies building toward enterprise customers: your standard connectors go live faster because reusable mappings are already in the graph. Your custom integrations move from months to weeks because the reusable majority is handled automatically, and your team's attention goes to the tenant-specific portion that actually requires judgment.
Your engineering team builds product, not integrations. Your PS team delivers go-lives in days.
The organization that builds the most comprehensive Integration Graph wins. Not because it has the best model, but because it has the best context.
Last Updated: May 04, 2026